Before I learned anything about SEO, I asked myself two very simple questions:
- Why does a website even need SEO? What happens if I do nothing?
- When I search Google for “best egg fried rice”, how does Google decide which webpage comes first?

I’ll answer them quickly:
- Answer 1: A website needs SEO to get search traffic. Without it, your site gets very few visitors – maybe nobody even knows it exists.
- Answer 2: The page with the highest relevance and authority wins. Behind the scenes, Google looks at keyword matching, website security (HTTPS), speed, and many other signals.
But “relevance and authority” are vague. So I dug deeper. And that led me to understand the three phases of how a search engine works.
Phase 1: Why SEO Exists – Problems & Motivation
The Problem
A search engine like Google has to discover, understand, and rank billions of web pages. If you don’t actively help it, several problems occur:
- Crawling failures: Google’s spider never finds your pages.
- Indexing errors: Your pages are seen but not stored in the index.
- Poor ranking: Even if indexed, they show up on page 10.
- Zero traffic: No one clicks because no one sees you.
→ Low rankings → low clicks → low conversions → lost business value.
The Motivation
By following search engine rules (not cheating them), you can improve your organic visibility – getting free, targeted traffic from people actively searching for what you offer.
That’s why SEO exists.
Phase 2: The Big Picture – How a Search Engine Works (Crawling → Indexing → Ranking)
A search engine is essentially a searchable database of web content. It has two parts:
- Search Index: Stores all the page information the engine has crawled, like a giant library catalog.
- Search Algorithm: A set of rules that decides which pages rank at the top for a given query.
The purpose? To give users the most relevant and valuable results.
Now let’s break down the three actions.
1. Crawling – The Discovery Step

What it is: A computer program called a “spider” (or crawler) visits and downloads web pages (URLs).
Purpose: Find content, discover new pages, and check for updates.
How crawling works – two main methods:
- Breadth‑first crawling: The spider starts from one page and follows links to others, spreading like ripples. This is the most common method.
- Depth‑first crawling: The spider goes deep inside one website – from homepage to category pages to articles to comments. Efficiency depends on site structure, page count, load speed, and crawl budget.
Webmasters can submit a Sitemap – like giving the spider a roadmap – to show which pages are important or recently updated.
Crawl frequency:
Google crawls your site more often if you update frequently with high‑quality content. New or rarely updated sites get visited less often.
2. Indexing – The Storage Step

What it is: After crawling, Google processes and stores the page content in its index database.
Purpose: Organize crawled content so it can be retrieved later for search results.
Processing: Google analyzes text, images, videos, tags, and metadata (title tags, meta descriptions, headings). Then it stores the information.
Key point – crawled ≠ indexed:
A page may be crawled but not indexed if:
- Content quality is low (thin, duplicate, or no value)
- Structure is messy (no heading hierarchy)
- There are blocking directives like
robots.txtdisallowing crawl, or a<meta name="robots" content="noindex">tag.
If you’re not indexed, you don’t exist in search results.
3. Ranking – The Ordering Step
What it is: When a user types a query, Google finds the most relevant pages from its index and sorts them – that’s ranking.
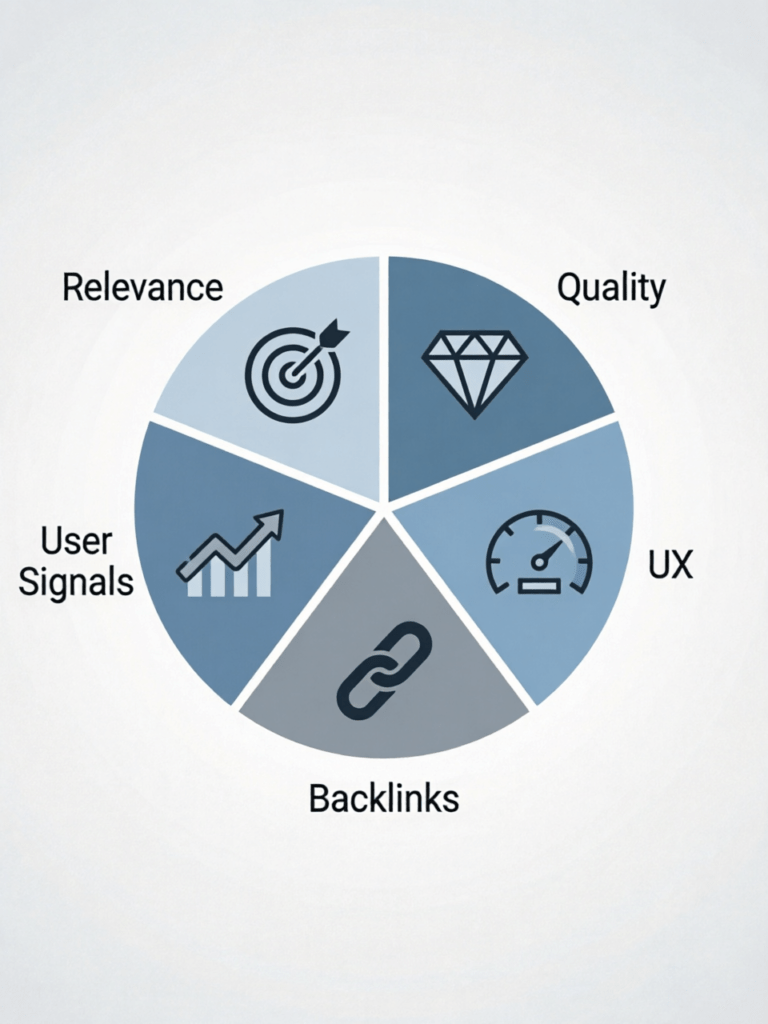
Main ranking factors (five categories):
| Category | Example question |
|---|---|
| Content relevance | Does the page match the user’s search intent? (e.g., “how to make cake” vs “history of cake”) |
| Keyword optimization | Are keywords used naturally in titles, body, alt text – not stuffed? |
| User experience (UX) | Is the page fast, mobile‑friendly, easy to read? |
| External links (backlinks) | Do other quality sites link to you? (acts as a vote of trust) |
| User behavior signals | CTR, bounce rate, dwell time – do people stay or leave quickly? |
Algorithm updates:
Google constantly updates its algorithm to better understand intent and reward useful content. As a beginner, you don’t need to track every minor update. Just remember: Google rewards helpful content and punishes tricks.
Phase 3: Micro‑Level Factors – What You Can Actually Control
Here are the specific things you can optimize today:
- Keywords: What do users search for? Does your page truly cover those terms (not just stuffing)?
- Content quality: Original, in‑depth, satisfying search intent (informational, navigational, or transactional).
- Site structure & accessibility: Clean URLs, internal links, mobile‑friendly, fast loading, HTTPS security (you mentioned security – it is a real ranking factor).
- External signals (backlinks): Do authoritative websites recommend your content?
- Technical details: Title tags, meta descriptions, schema markup (structured data).
The above is a high‑level overview of the core ranking factors. Among them, content quality and authority are the most critical. In the next article – SEO Cognitive Series (Part 2): Content Quality & Authority – we’ll dive deep into E‑E‑A‑T, search intent, content depth, and backlink building. Stay tuned.
Final Summary (What You Need to Remember)
Understanding how search engines work is the foundation of SEO. Only when you know how crawling, indexing, and ranking function can you optimize effectively.
Ranking → Make sure your pages rank well: relevant content, good UX, backlinks, positive user signals.
Crawling → Make sure spiders can find your pages: submit a sitemap, build internal links.
Indexing → Make sure spiders want to store your pages: produce quality content, don’t block them.
📚 SEO Cognitive Series
- • Part 1: How Google Search Works – Crawling, indexing, ranking explained.
- • Part 2: Content Quality & Authority – E‑E‑A‑T, search intent, backlinks, UX.

About Shelldy
An ordinary practitioner learning SEO from scratch. By day, I work in the internet industry; by night, I turn what I’ve learned into articles. I believe that honest learning records are more valuable than rehashed tips. Feel free to connect and exchange ideas.
Pingback: SEO Core Knowledge Checklist: From How Search Works to Actionable Steps | whaoseo
Thanks for your comment! That’s actually the internal link I placed in the article to guide readers to Part 1 (How Google Search Engine Works). If you haven’t read it yet, feel free to click the link above 😊
Let me know if you have any questions about crawling, indexing, or ranking — happy to discuss!